The Design of an Internet-Based Collaborative
System Architecture
Francis Chan & Mark D. Spiller
Computer Science 269, Spring 1996
Recently, the Internet and WWW have undergone
tremendous growth. While the number of users, information available and
network traffic have grown exponentially, the Internet's full potential
has not yet been reached. Currently, Internet sites are primarily used
as advertisement boards to display (static) personal or organizational
information. Interactivity can be enhanced and simple data reception applications
(e.g. registration, survey, product order) can be provided with the use
of forms and script files (such as Perl) on servers. Technologies such
as NeXT's WebObjects create web pages on the fly according to users' input
parameters. Moreover, Java has also been widely adopted by web page publishers
to provide interactive applications. These applications range from simple
animations to multi-user network-connected programs (such as real-time
whiteboards or games).
We foresee that the WWW can provide more than just a means for information
display and gathering, with it growing to become a platform for design
collaboration. Internet-related technologies such as telephony over the
Internet, data pre-fetching and downloading to clients, etc. have demonstrated
that the WWW has the potential to break traditional geographical and media
barriers of collaboration that are currently limited to phones, faxes,
tele-conferencing, physical or electronic mail, etc..
Machine independent front-ends are made possible by Netscape and Sun
(Java), etc., who have implicitly absorbed the hidden costs of providing
(true) platform independence. The Java network interface and execution
environment has presented a new opportunity and paradigm for distributed
computing and collaboration, when connected to a supporting network of
tools that we plan to provide the infrastructure for.
We believe that many developers would take advantage of the opportunity
to build content for the system that we are proposing and designing. Although
the use of these new servers would consume CPU cycles on their machines,
the costs could be justified for many of the same reasons that people and
companies set up web servers and network links today, such as personal
fame, the promotion of company tools, and as beta test-sites for future
services. The creation of such tools would also fit in both with the core
philosophy of organizations such as the Free Software Foundation, which
strives to provide quality software for multiple platforms on the Internet,
as well as with the evolution and maturation of a pay structure for commerce
on the Internet, which should provide additional incentive for content
creators. In general, user and developer enthusiasm for Internet technologies
such as HTML and Java have reached a critical mass that previous distributed
architectures, such as CORBA, have not achieved. When tied together with
a broad user base, the current (improving) infrastructure of the Internet/WWW
as well as the related technologies are mature enough to warrant (and support)
a collaborative design environment using the WWW.
In this paper, we will describe a network environment that gives users
with various levels of computing power and available bandwidth access to
tools provided by platform-independent developers across the Internet.
Services and features that form the infrastructure of our system as well
as collaboration schemes and methods will be discussed. We will
demonstrate how the three-level system supports efficient addition of users
and tools and a migration plan which allows more features, such as increased
accessibility and security, to be incorporated in the future. Our design
and trade-offs decisions made are based on our view of usage patterns and
future technological trends which we will elaborate on throughout the paper.
Our goal in developing this system is to provide the architecture, protocols and general services first, and then attempt to gain the support of the Internet community to make it a robust, flexible, and rich environment for users and designers.
We have followed quite closely the development of Internet-related technologies
and trends. Our observations and predictions are:
Main Server - Central server for user and tool registration. Takes on extra
security responsibility in the highest level of design.
Tool - Applications or services developed and registered by any
individual or organization, accessible to the network through sockets
or some other similar method.
Data Server - A machine on the net that stores users' session and data
files. Acts as home location to users it serves. A user can make use
of multiple data servers if desired.
Meta Server - A networked machine that provides location services as
well as stores the location of users' profiles and tools on the network.
HTTP Server - A traditional Web server.
User Network Interface - A web browser (such as Netscape) which supports a
platform-independent execution environment such as Java.
We envision that our system would be extremely beneficial to a wide range of users ranging from people working from home to engineers in traditional offices to mobile users off-site. The system can accommodate computer terminals that range from a T3-connected high-end workstation to a PDA that has limited computing power and is connected to the Internet by low-bandwidth wireless modem. For project team members (especially those geographically separated), it is very important that the remote individual has an efficient means of figuring out what other people in the group are working on, how the project as a whole is going, and how his piece fits in. In our collaborative design system, people could put information such as their schedule for the week, what they are currently working on, the tools/files/modules that they are using (including version numbers), what they have completed from their task-list, etc., on-line. All participants would be able to benefit from this; the designers themselves would learn to better schedule and manage their work, the team as a whole would gain more knowledge about project problems, and management would be more aware of project status in general. The scheduling and task-lists could be used to generate automatic weekly reports. In addition, the use of network tools in an online collaboration environment would allow MIS to track which tools are actually being used, in order to gather information concerning licensing, upgrades, and general usage/performance.
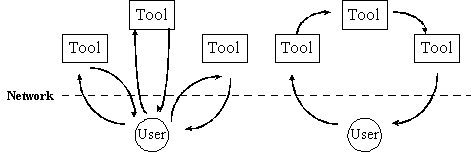
The support of tool-to-tool/server-to-server communication over the
Internet is also extremely valuable as it allows teams or companies that
are not connected by LANs or WANs to pool resources, concentrate on strengths,
and collaborate on different stages and portions of a project or a design
(i.e. workflow). The increase in accessibility of applications, both in
variety and availability, provides a flexible system that allows powerful,
complex actions to be performed, similar to pipes and other filters on
the UNIX command line. It also presents a potential shift in computing
to servers and is particularly advantageous to users with low computing-powered
terminals, such as "Network Computers" or PDAs. The one time
transmission and reception of requests and results also great favors users
with a limited bandwidth connected to the Internet (e.g. mobile users)
as well as potential productivity even after disconnection (e.g. a user
can start a job from his terminal and instruct the result to be saved at
his requested data location. The user does not need to remain connected,
monitoring status, once the job has begun, which could make the user less
susceptible to local network failures.).
Communication overhead of Traditional Client/Server vs. Server-to-server
| Mode of Client/Server | User to Tool Communication | All Tool and User Communication over the Network |
| Traditional (Server/Tool only) | 2n* | 2n |
| Server-to-Server capability | 2 (constant) | n + 1 |
*n is the number of tool that that the user needs to deal
with
The World Wide Web holds the potential to increase the flow of information
between and within all computerized organizations. Today, one can find
Intranets being used to distribute specifications, release product specifications,
and exchange other data. In the future, with the increases of network-centric
computing and business structures such as virtual corporations, collaboration
over the network will increasingly become a reality.
We define collaboration as working together towards a common goal. Collaboration
can include many facets, many of which are not initially obvious and will
only become apparent when the infrastructure is in place to support them.
Several basic pieces that would certainly be useful to design team members
would be:
Collaboration and sharing can encompass a number of modes and granularities,
including:
This is straight-forward, and already offered by http servers. This is ideal for
project documents and different individual views of projects.
This is also already offered by http servers.
This service is already available to designers whose projects span cross-mounted
NFS disks and use CVS, and on multi-platforms with LAN-based software configuration tools such as ClearCase and Continuus/CM. Ideally, it could be expanded to cover cases in the global network.
This is appropriate for applications such as whiteboards, where speed
is desired over versioning.
Our intention in this design document is to make the system support
information sharing in a general manner in order to support the above functionalities,
as well as additional variations (see System abstraction). For instance,
for the fourth case above, real time updates might be handled in several
different ways, such as:
| Update Model | Level of User Inter-dependency | Bandwidth Requirement | Usage Example |
| Client updates upon an explicit command or operation | Moderate | Client dependent | Workflow
(e.g. compilations) |
| Client polls server on a time interval | Low | Constant | Progress update |
| Server maintains check-out logs, updates clients whenever new updates are received | High | Proportional to updates and number of users | Whiteboards |
Such different possibilities are all easily supportable on the generic
distributed system discussed in this paper. Tool builders will have the
ability to create, monitor, and test different implementations of tool
applications on the network in order to gain information on usage patterns
and thus determine the optimal fit for their services.
Our goal is to build a generic architecture and infrastructure that
tool builders will find very easy to integrate their tools into. Thus,
the system will be flexible and modifiable through the addition of innovative
tools with the desired functionality. An example here would be the different
types of collaboration applications mentioned previously. A tool server
could be built to support any variety of client polling, client explicit
update, or server update, depending on the application features that were
desired.
Similarly, just as the update paradigm can be varied, so also can the
form in which data and commands are transferred between system participants.
This information transfer can include files and single commands, as well
as authentication data. Designers can take advantage of their ability to
easily add servers to perform translations between tool-specific data formats
(i.e. a translator to convert files from ASCII to binary, or from Word
to Frame).
A key concern in our distributed system will be how users would handle workflow over the WWW. Clearly, as project size increases, users will not be able to manage the complex set of dependencies among the network tools without additional support. Following the model given above, a server can be created that would offer the functionality of a "network makefile." An example of this follows, for a transaction server.
In all of the levels of our system described in this paper, an automatic
listing of all of the tools used by the user is maintained in a type of
"bookmark" file-personal profile. From this, a tool could be
designed that graphically presented all of the tools and files currently
in use for a given project. The tools and files could be arranged in a
design flow that indicated the existing dependencies.
A "transaction server" would need to be written to complement
this flow tool. This server would include a piece that wrapped around the
user's entry point into the system and mirrored all commands sent to the
transaction server (alternatively, all of the commands could be sent directly
through the transaction server and re-routed there. This might have different
effects on the servers, for example, in terms of performance, but would
still be scalable, since many instances (and variations) of transaction
servers could be made). The transaction server would keep track of where
in the design flow events were occurring, and could respond in a variety
of ways based upon user preference. For instance, it might simply prompt
the front-end to warn the user that dependencies had not been updated yet,
or on the other extreme, it could proceed to make all of the necessary
updates and then proceed with the desired command.
Several issues that would have to be considered in this design would be how transactions would be maintained in the case that designs are passed directly from tool to tool (as opposed to always from user to tool and back). In this case, a variety of solutions might be implemented with the server. For instance, user information could be passed on at every point in the design flow, so that servers farther down the line would know whose design was being worked upon and how to reach the designer (this would also be useful for the sending of status and debug information, as well as to keep track of fee information in future systems with payment requirements). This might be included as the equivalent of "header information" in the command exchange API decided upon by the tool designers (or perhaps in the future as a common API set in the infrastructure by the system designers (us)).
Tools location service provide a graphical user-interface for users
to peruse. Similar to user registration, there will be a URL for tool registration
where an automated procedure is run. Tool providers will be asked to provide
the following information regarding their tools during registration:
To deal with malicious tool registration, we could:
Since someone other than the tool registrant has to remove the invalid site entry from the tool location file, "super-user" intervention is inevitable when dealing with invalid sites. We chose Option 3 since it is the most scalable, easily automated and requires minimal human intervention. We assume that the number of new services can be large but that it would be within reason for several people to check problem cases. )
In the case that people do not like the hierarchical structure provided by the tool location services or find that the organization or categorization is not helpful, we anticipate that, based on recent examples with the Internet, people will come up with a new directory service for our distributed collaboration system (and get their US $165 million IPO dollars like Yahoo!).
In a distributed system, there are many tradeoffs that might affect
where data is stored, both in the long term as well as temporarily. Major
factors in data placement include security, accessibility, performance,
and fault tolerance. As we have mentioned in earlier examples, the general
architecture that we are designing makes it easy to add servers that can
support varying amounts of data stored on the network.
The most secure model would have the user keep the machine in standalone
mode, with all of the (trusted) tools installed locally and no network
access. While this is very secure, it is not very interesting in our design
vision, since this setup would prevent the realization of any of the benefits
of networking.
A slightly less prohibitive solution would be to maintain data on a
secure "home server" that was connected to the outside world.
This server might serve documents in an encrypted way such that only the
owner could access it (perhaps from anywhere in the Internet, or perhaps
in a locally restrictive manner) or could send it securely to trusted tools.
Another advantage in this case would be that all of the user's data would
be in one central location which could easily be backed up to archives.
Another progressively less secure option would be to store intermediate
or all relevant data on capable tool servers. This would be beneficial
for performance, especially in cases where data required continuous, repetitive
processing in tool-specific data structures (i.e. a schematic being edited
on a remote server but displayed locally, as is with the Berkeley OCT CAD
tools. One would generally not want to reload the entire design every time
an edit occurs, since the downloading and parsing would be too expensive.
It would be much more beneficial to keep the intermediate data on the tool
server, sending only the commands and not the actual data each time). An
additional level of performance gain would be to permanently store the
data on the tool server (perhaps for a fee). Disadvantages would be the
fact that in this scenario the user must trust the tool servers, and thus
loses security. Additionally, if the tool server went down, the data would
become unavailable (unless it was replicated). An advantage, however, would
be that the load time might be reduced considerably.
The least secure model, but one which might be very well suited to the
use of network computers, would be to store data on specially created "network
data servers." In cases where stripped-down machines might not have
sufficient local storage to store data locally or there were network advantages
(i.e. bandwidth or latency) to storing on a data server nearer the backbone,
we think that it would be reasonable that customers might rent storage
space. Again, as above, this performance gain might come at the cost of
security and accessibility (if the server went down). Additions such as
the ability to download data to a local site for backup would probably
be required.
Finally, we envision that it would be possible for tool and data server designers to build into their servers some form of data migration which might take advantage of the effect of several of the data location possibilities mentioned above. Since these options would vary depending on the server and the applications it was supporting, we will not cover these issues in the paper, but instead simply state our belief that the server could be written in a way that would support any reasonable functionality, with the ability migrate the data in a way that would optimize the connections between the user/data and tools in terms of time, latency, and cost.
Our architecture makes it so that the entire system doesn't need to
be re-written to add additional replication services for data servers.
New servers can be added with replication functionality without disrupting
the system, or existing servers can be given user options (backup vs. performance,
etc.) to provide different levels of service. The issue of replication
does pose problems in choosing how to maintain consistency, but since this
will be dependent on the actual services desired/offered and the implementation
chosen, we will not address this in this design paper.
There are three levels to our distributed system, starting from Level
1, the simple single-server, limited user, tools and security support,
to Level 3, a fully integrated, scalable and secure system. A logical migration
and system update path is provided with a view to maintaining backward
compatibility throughout system improvements and addition of features.
Issues regarding distributability, accessibility, scalability, consistency,
security and session administration will be explored in detail for each
level.
A table summarizing the three design levels as follows:
| Distributabilty | Accessibility | Scalability | Consistency |
Security |
|
| Level 1
Central User Server |
All tools and users limited on one server | Low - limited by central server | Limited by server | Strong. Only copy of (local) data allowed | None |
| Level 2
Fully Distributed System |
Distributed tools and users | High | Scalable | Generally Strong (Varies across tool servers) | Varies across tools |
| Level 3
Secure Distributed System |
Distributed tools and users in a secure environment | High
(Same as Level 2) |
Scalable
(Same as Level 2) |
(Same as Level 2) | Integrated |
Distributability - Ranges of network locations of tools and access points of users.
Accessibility - Availability of user profiles and location services.
Scalability - Ability of the system to flexibly handle the addition of users and tools.
Consistency - Possibility of different copies of existing user profiles or location data on location
servers, where strong = smallest possibility
Security - Availability of authentication and privacy
in the exchange of data.
The Level 1 system is built on top of a single server (e.g. HTTP, NFS)
serving just personnel who have access rights to that server. It serves
as providing the backbone to future extensions to Level 2 and 3. User interfaces
and personal profile format can be retained, while tool-to-tool communication
protocols can be extended to server-to-server communication over the Internet.
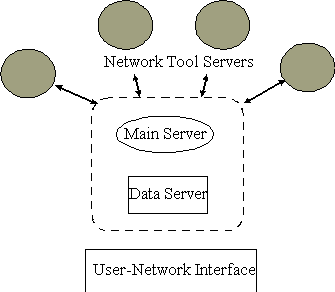
High-level description of Level 1 system
The Level 2 system relieves some of the duties of the centralized server,
and extends the Level 1 system to support the scalable addition of users,
data locations and tools that can be accessed across the network. A main
addition to Level 2 is the incorporation of meta servers.
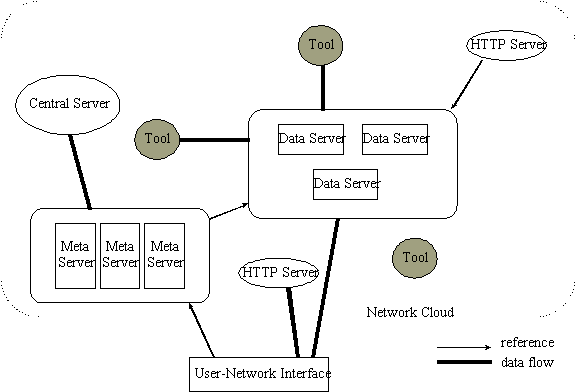
High-level description of Level 2 System
(Level 3 is similar but with extra security flow.)
Meta servers play the important role in our design system of insuring that the users' profiles and collaboration information are always accessible in as recent a form as possible, given tradeoffs.
Modifications in tool locations (i.e. additions or replicated copy elsewhere, etc.) are done with the central server, which then propagates the updates to the meta servers in a lazy fashion. Updates are thus performed transparently and there is no need for users to manually update their profiles.
When a user begins a (design) session by logging on through the network interface, the first site accessed will be a meta server (meta servers will have well-known, easily remembered names, and thus will be easily reachable by the user), from which the user downloads the profile In general, meta servers are data storehouses, maintaining huge sets of user profiles as well as lists with the names and locations of all of the other meta servers and tool location servers in known existence (This follows with our assumption that data storage will become huge and cheap).
It is critical that users be able to download their profiles regardless of the status of their local (commonly-used) meta server. Without the profile, the user is in a situation where it would be very difficult to find the tools and services needed for a project, much less use them intelligently, since many of the addresses and APIs could be at utterly different levels of abstraction. Thus, meta server data is replicated across all meta servers to ensure that a fairly recent version of all user profiles are available somewhere on the network. We decided here to trade weak consistency for better performance. We assume that people do not edit their environment very often, and that in general they will not change servers so often that any changes that they had made in a recent time would not be present (we are also assuming that meta servers are placed on a regional basis, i.e. West Coast, Northwest, ...). In the case where a user had made a change and knew that he/she would become mobile soon, the change could be forced to propagate to the known server in the new region. Otherwise, the user may have to suffer a brief window of inconsistency of the data (the same with tool location inconsistency due to a site change) on the meta server. For the non-mobile case, it would make sense for the servers to batch changes to be stored to stable storage, and then process them and send them to the rest of the meta servers in the region's off-peak hours. The other meta servers in turn would process this additional data in their region's off-peak hours as well. In this manner, although it might take a day for the change to propagate, one would have the least effect of replication on the performance of the meta servers (assuming changes and crashes were fairly infrequent. Since the changes were on stable storage, fairly few of the updates would be permanently lost in case of a crash). This is necessary to prevent the higher network cost and server delay involved in strong consistency, which would require the propagation and confirmation of changes to all (or a majority voting share, in a quorum system) of the replicating meta servers.
Meta servers would also be used to provide group collaboration profiles. Part of a profile deals with the access rights of the data being shared, which includes information such as whether the data is local to a member's or group server, whether it is with a tool, or on rented space, as well as the type of read/write policy that is applied. Thus, the users would be able to use the meta servers (as well as the tool servers, if they had the option) to govern the collaboration and consistency of the shared data. Special meta server access tools would allow groups to modify these policies for their profiles. Collaborating groups could still choose the desired level of consistency by choosing the type of tool and data servers and their consistency/accessibility levels.
The Level 3 system goes on to provide the same features and functionalities
as a Level 2 system but with user and tool security integrated. The performance
of the system in storing, retrieval, communication, etc. may decline due
to the bearing of extra overhead in data encryption and decryption.
A table summarizing the characteristics of the three session administration
scheme is as follows:
| Session Control Type | Bandwidth Requirement | User Convenience | Security Requirements for Tools |
| User Login Only | None wasted | Least | No change |
| Complete Tool Login | Most wasteful | Highest | Standardization |
| Tool Login as Needed | None wasted | Moderate | Standardization |
A central security provider is required especially in Level 3 design. However, issues such as:
These questions may probably not be answered until a successful (feasible, secure and broad user base) mode of electronic commerce emerges.
In order to do online services, people will need to trust some organization(s)
(e.g. commerce servers, cyber banks, credit card companies) for fund transfers.
In we do plan to handle fund transfers in the future, we will have to ride
the wave and explore ways to make use of the services that gets adopted
by the majority (unless UC Berkeley is generally considered a trusted place
).
It is our intention to build the infrastructure for the system described
in the previous pages. We have begun with an implementation of level 1
as a feasibility study, which will be used to observe the design in action
and confirm its potential benefits. From there, we plan to expand the system
to level 2, and then build sufficient interest to get the Internet community
involved and with its help eventually raise the design system to level
3.
Currently, our research group (working with Prof. Newton) is engaged in building infrastructure and testing the feasibility of level 1. We have built several tools, including a Finite State Machine editor and a group status monitor. The FSM editor:
http://www-cad.EECS.Berkeley.EDU/~wleung/fsmb4/demo.html,
makes use of a machine-independent front-end written in Java that can access two simple servers over the network, one of which is used to load and store designs, the other of which runs the nova state optimization tool on the current design. The group status applet:
http://www-cad.EECS.Berkeley.EDU/~mds/GroupStat/GroupStat.html,
makes use of a similar server that keeps track of specified users in
our research group. We plan to (and are committed to!) demonstrate a system
at the Design Automation Conference University Booth in June in which a
user will:
(In fact, we'll be working on this as soon as we finish this paper ).
Recent developments in high-technology have shown that it is often the
market and user community, not the standards-setting bodies, that drive
the market and technological direction (case and point: Microsoft). We
have, therefore, deliberately avoided stringent requirements to many open-ended
issues in our design so as to allow a flexible implementation and extension
to our system and the tools that are to be incorporated; in doing so, we
also make sure that our eventual goals are met -- encouraging and being
the driving force behind the shift towards Internet-based collaboration.
As a research institution, we are capable of providing a totally public
architecture (up to level 2). However, we may not have the leverage or
critical mass to force a security or payment standard and will have to
allow tools to implement and adopt their own security and payment methods.
We hope that level 2 will show the possibilities of this system and generate
sufficient impetus to drive industry to take it to level 3. A likely deployment
of Level 3 is the adoption of our system (protocols, user interfaces, etc.)
within organizations, similar to what many companies are currently doing
with Internet/intranets and deployment of specific security and protection
schemes. The same architecture can be retained, but access and usage can
be limited to inter- and intra- corporate collaboration
To date, there have not been many published papers in the area of Internet-based
collaboration. This explains our lack of references for this paper, as
our design is based on and inspired by the CS 269 class lectures and the
many intellectually-stimulating papers in the course reader . In addition,
our group's research into the area of distributed CAD environments has
lead us to believe that we are currently among the leaders and on the cutting
edge of technology in regards to Internet-based collaboration. It is our
goal to assist in the paradigm change to distributed computing and collaboration,
if not achieve it ourselves (i.e. "Change the World").