Team and Organization
Motivation: The distributed information-technology platform of the
future offers amazing opportunities in terms of data gathering,
processing and dissemination. Ubiquitous, high-speed networks offer the
promise of access to unlimited computation, communication and storage,
and potentially could help to address burning problems such as energy
shortage, health care and national security. A totally unexpected result
of this evolution is a return to large compute/storage/communicate
centers, which were once thought to be an endangered species after the
advent of the personal computer. Unfortunately, the "infrastructural
core" of our distributed IT platform also turns out to be
energy-intensive. Data centers are the fastest growing segment of
the IT platform in terms of carbon footprint, and the appetite for their
services is increasing exponentially with no slow-down in sight.
Huge improvements in energy efficiency are essential if we want to maintain
this growth while staying economically and environmentally healthy.
Similar concerns apply to the defense community. From the very beginning
of computing, large-scale systems have been critical to the nation's
security. They are used for a variety of applications including
stewardship of nuclear weapons, intelligence gathering and analysis, the
design of weapons and armor, and to support fundamental defense research
in fields such as material science. The demand for computing cycles to
support these missions has been insatiable, and led to a long history of
Defense R&D.
In a future where data will not only come from classical computing
systems as it does today, but also from millions of sensors and mobile
devices that already permeate significant parts of our life, the
requirement for energy-efficient large-scale data computation will
explode, both for defense and commercial use. Moore's Law driven growth
in computing power offers to address this demand. However, the end of
Dennard scaling and hence the scaling of energy/operation makes improving
the energy-efficiency of computation a critical problem. Novel solutions
exploiting heterogeneous processors in combination with innovative memory
and interconnect architectures, are necessary to make an inroad. MuSyC
proposes to investigate these in collaboration with the GSRC Platform
Center. Our contention is however that substantial additional benefits
can be obtained by eliminating the built-in inefficiency that
exists in large-scale systems. For example, even under very light load
conditions, the power load of a typical data center still runs at least
50% of maximum (data centers typically run at approximately 20-40% load.
Vision: The need for an effective and adaptive power management
strategy that dynamically balances supply and demand in light of
performance, cost and reliability constraints is a common theme emerging
in virtually all large-scale distributed systems envisioned for the
coming decades. The MuSyC perspective is that the only viable solution is
a holistic distributed "measure-predict-and-control" energy management
solution that includes all components of the system at all hierarchy
levels. Our research vision is to develop a multi-scale cross-layer
distributed and hierarchical management scheme that ensures that energy
is only consumed if, when and where needed. This must be accomplished
while serving dynamically changing workloads with stringent latency and
reliability constraints, and requires exploiting all the knobs available
at all levels of the design hierarchy.
While the problems and solutions addressed in this theme are applicable
to most large-scale system (such as green buildings or complex airborne,
seaborne or automotive platforms), we have selected the data center of
the future as a compelling driver for our efforts. Truly compelling goals
to pursue are the concept of "energy-proportional" computing (as first
envisioned by L. Barroso), and to "do nothing well", minimizing
energy consumption when nothing (or little) is being done.
We therefore envision a future large-scale computing systems capable of
achieving orders-of-magnitude increases in performance while at the same
time reducing the carbon footprint by one or two orders of magnitude. To
achieve such an unprecedented improvement in energy efficiency while
meeting the demands of future workloads we have to consider all the major
system components (computation, networking, storage, cooling and power
distribution) and their interactions at multiple hierarchy levels
(hardware, virtualization layer, operating systems, protocols,
applications). This will lead to balanced systems that, by adaptively
examining performance needs at all levels of scale, run far more
efficiently, even in the face of the demanding and diverse workloads of
the future. The results of our effort will drive the design and operation
of heterogeneous computing systems of the future, from SOC processors to
multi-megawatt distributed datacenters.
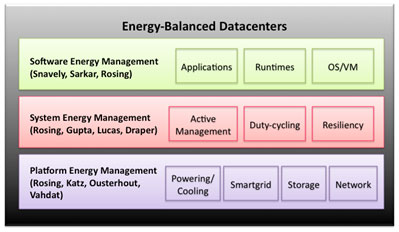
The overall structure of the theme in terms of global organization,
research topics, individual contributions and their interrelationships is
detailed in this figure.
The team's contributions touch on critical elements of future datacenter
systems across multiple levels of scale. These include energy management
strategies at the software, system, and infrastructure level so that
power budgets dramatically are reduced while meeting performance, latency
and reliability constraints.
To quantify the opportunities for energy management, we will extend our
performance prediction methodology to understand the nature of the
emerging workloads, applications and their needs. We will contrast these
software requirements with emerging technology trends to predict many of
the critical barriers to realizing performance and energy efficiency in
future large-scale systems and thus direct our research. We will develop
tools and methodologies needed to analyze the interaction between future
workloads and architectures. This will lead to significant improvements
in energy efficiency of the software infrastructure as a whole. To ease
the burden of application developers, we will develop energy efficient
techniques within runtimes (.NET and Java) and operating system
(OS)/virtualized machines (VM) capable of effectively utilizing novel and
heterogeneous hardware and software architectures. It will also allow us
to explore a three-fold strategy for system energy management. First,
workload allocation and scheduling will be performed so as to ensure
energy-proportional operation in the active states. Next, duty cycling
of the servers is complemented with proxy processing to ensure
availability with large energy savings. We will also develop strategies
for trading off energy and resilience to enable scaling the energy
requirements of applications and hardware within an applications error
tolerance. Lastly, the infrastructure management strategies provide
smart links to sensors and controls needed to efficiently connect the
components, store the data, and provide the electricity to power and cool
the overall system.
Measures of Success: The goal of this theme is to design
large-scale computing systems capable of achieving orders-of-magnitude
increases in performance while at the same time reducing the carbon
footprint by one or two orders of magnitude through a holistic
multi-scale approach. Progress towards that goal will be measured through
prototyping on existing or experimental testbeds (including data center
containers at UCSD and USB) combined with simulation and emulation.
|



