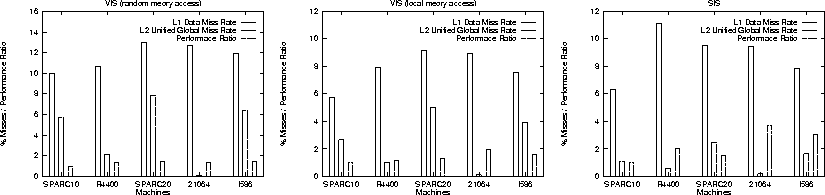
We selected three applications from our benchmark suite - SIS, VIS and IRSIM, and simulated the caches of the different machines on them. We wanted to observe the correlation between performance ratio and the L1 and L2 miss rates for the selected applications. A single input example was chosen for each application toward this goal. Figures 4 and 3 shows the performance ratio and miss rates in the form of a bar graph. Table 3 shows the memory references (reads and writes) as a fraction of the total number of instructions.
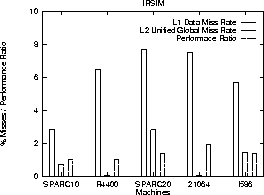
Figure 3: Comparison of L1 and L2 miss rates and performance ratios for
IRSIM
Figure 4: Comparison of L1 and L2 miss rates and performance ratios for
various applications

Table 3: Read and write percentages for various applications
A number of general observations could be made from the output of cache simulation. The number of instruction misses in both L-1 and L-2 caches were always very small. Therefore, we feel that instruction misses do not affect the performance of the machines. Writes dominate reads for data references to the L-2 cache since the L-1 cache in all machines is write through. On the other hand, reads dominate writes for the L-1 cache. We found that the size of the L-2 cache of 21064_182 (largest at 4M) was sufficient for both data and instructions for all the applications except SIS. But, the sizes of the other second level caches was not sufficient for any application. We now analyze the cache simulation results for the three applications.
For the case of random memory accesses, we observe that Sparc20_100 has the best performance overall even though its second level miss rate is higher than that of 21064_182. This is because in 21064_182, even if a hit occurs at the second level, the small number (16) of TLB entries causes TLB misses, increasing the second level hit time. Sparc20_100, on the other hand, has a 64 entry TLB with 4K page size. So, a hit in the second level cache (256K) will always result in a TLB hit. Therefore, the access time for the second level cache is smaller and in spite of a higher miss rate, this system performs better 21064_182 running at almost twice the speed.
For the case of local memory accesses, the cache misses are not significant. Note that the increase in the fraction of read/write instructions (Table 3) is due to the nature of BDD algorithm. Also, local memory accesses reduce the number of TLB misses significantly, making 21064_182 perform the best, because of much higher clock speed.