Overview
Of course, users of the language will want to generate executable code from
an actor description, in order to simulate or eventually implement an actor
on some target platform. The CAL software infrastructure is designed to make
the creation of code generators as simple as possible.
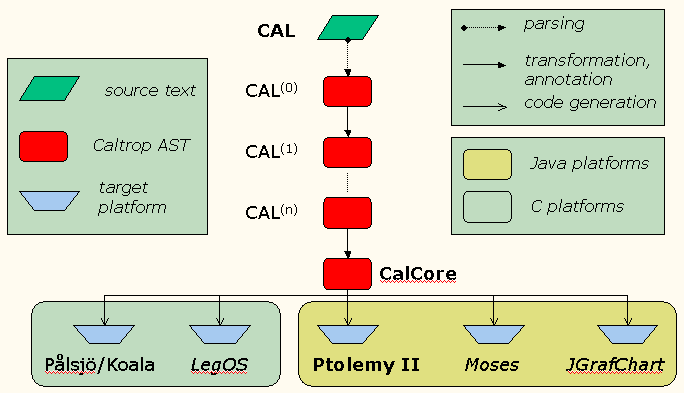
Figure 1: Cal code generation overview.
The general idea is that as much of the work as possible is
performed in the source language itself---simplifications, optimizations,
checking, annotations that extract static information from the source code,
etc. Many of these steps are generically useful, and we are providing a suite
of little programs that transform and annotate a simple core data structure.
Platform-specific compilers can choose from these modules and eventually add
a last step that creates the actual code.
We have defined one particular chain of these transformations
that creates a canonical form of an actor (called CalCore) which seems
to be useful as the basis for code generation to a number of different platforms.
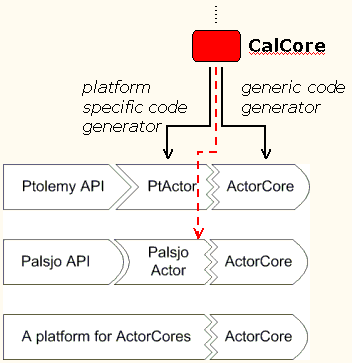
Figure 2: ActorCore Architecture
In many cases, especially when prototyping code generators,
it is possible to generate an adaptor between a generic form of the actor
and the platform-specific execution engine, rather than to generate a complete
platform-specific actor from scratch. There exists a code generator that produces
such a generic actor for the Java platform, called an ActorCore.
Code generation contexts: platforms and profiles
By design, CAL is intended to be usable in a wide variety of
application domains -- from general purpose applications (where actors would
play a role similar to, say, JavaBeans) to embedded software to hardware.
From a programmer's perspective, these environments differ in the kinds of
data types they support, the available function libraries, and the kinds of
operators. Defining one language for all these domains runs the risk of either
falling for the common denominator approach, leading to a language that feels
'too small' for the more liberal platforms, or the risk of designing a common
multiple, which will then be difficult to implement on the more constrained
platforms.
The solution that we are aiming for is to keep the language
itself parametric, i.e. to leave design choices such as type system, operators,
and basic functions open, so that special versions of the language may be
created for specific platforms. This description, called a context,
is itself an XML document -- see this concrete
example (which describes the Ptolemy context, and is evolving as we complete
our code generation path). It contains information about operators, substitutions,
types, etc.
This, of course, means that in general actors will not be portable
across platforms, because they make use of properties that are only part of
the specific CAL dialect. To an extent, this is in the nature of things --
an actor implementing a GUI component is of little value for describing a
piece of silicon. On the other hand, there may very well be actors that would
be useful on different platforms, but are not portable because they have been
written in different dialects.
In order to provide a framwork for the construction of dialects,
we aim at defining language profiles. Such a profile would describe
a set of capabilities (data types, operators, library functions) that characterize
a particular kind of platform. It serves as a contract between CAL
implementors and CAL users (i.e. programmers writing CAL actors) -- implementors
of CAL would know which capability to provide, and users would know which
to rely on in order to make an actor description portable across all implementations
that realize a particular profile.
In addition, we aim at defining a structure among these profiles,
not unlike an inheritance hierarchy: if a profile A is a sub-profile of B,
then any actor that conforms to profile A will also run on a platform conforming
to profile B (and produce equivalent results).

