|
|
Diva: Dynamic, Interactive VisualizationThe Thanksgiving white-paper
IntroductionDiva is a software infrastructure for visualizing and interacting with dynamic information spaces. Our specific area of interest is the visualization of complex hardware and software systems during the design process. This encompasses a wide variety of systems, ranging from software-only systems to embedded hardware-software systems to giga-scale VLSI designs. Although differing tools and methodologies have traditionally been used in each of these classes of design, work in "component-based" software design (...) and "interface-based" hardware design (Rowson and Sangiovanni-Vincentelli) suggest that the different fields are growing increasingly similar over time. Regardless of whether the fields ever converge, we believe that they share common complexity challenges and objective functions, and will benefit greatly from the same types of visualization components. We characterize the design process, particularly in the early stages of design, as one of exploration of the design space. Initially, the problem itself may be very poorly understood, and much of the early part of the design process is spent in better understanding the problem, rather than working towards a solution. The designer requires artifacts and media that help him or her to visualize properties of different system configurations at a very high level, in order to understand the likely impact of different design choices. The system will be very incompletely specified, and so rapid exploration and evaluation of different axes of the design space is vital to understanding the problem space. In many respects, the design of complex hardware-software systems is a "wicked problem" (Rittel and Webber 1969), and so solutions are not amenable to mathematical or algorithmic analysis, but require judgment, foresight, and understanding. In later stages of the design process, the problem changes becomes, in some ways, "larger but simpler." Once a system is refined further, it is possible to conduct experiments on executable portions of the system, or to perform simulations to discover and analyze the expected behavior of the final system. It is this domain that traditional visualization tools address. Nonetheless, we believe that rapid understanding even at this level requires that visualizations take on a more dynamic and interactive character. Because simulations are typically long-running and compute-intensive, a designer is unable to effectively explore alternative solutions and perturbations of design parameters. One of the goals of the Diva project is to build partial but immediate information presentation into the kernel of the visualization architecture. In other words, a little information now may well be better than a lot of information later. High-level goalsDiva came about through the convergence of several key factors. One was simply a frustration with the tools we have for building our own software systems, and the realization that there is a whole uncharted field of interesting research that we can do to solve these problems. In effect, this is Eric Raymond's "itch". One of the problems we see with conventional approaches to visualization in systems design is that "visualization" tends to mean after-the-fact, impoverished summaries of an execution or simulation. In many cases metrics are devised to provide abstract, low-dimensional views of processes (for example, "plot cost against time over the course of execution"). While such abstractions do provide a certain amount of insight into some facets of a system's behavior, they are of little use when it comes to understanding why the system performs in the way that it does. To put it another way, "forget the summary, just show me what happened." Furthermore, although parts of the system are often described in a graphical notation (state charts, dataflow diagrams, circuit schematics, and so on), execution and algorithm visualization is a completely separate process. As a result, the designer must piece together information from disparate sources to attempt to understand the system. One of our visualization principles is that visualization of the system architecture and/or algorithm should be combined with the visualization of the results -- and where possible, placed in the medium of the graphical input notation itself. For example, a circuit schematic could be dynamically annotated with power consumption and delay estimation as the designer modifies it, or an asynchronous, buffered network could animate buffer overwrites during the course of execution. We believe that the insight provided by these types of visualization will provide immediate insight into the behavior of systems in ways that simple charts cannot. One of the problems with complex systems is that understanding is often gained through simulations, which are compute-intensive and long-running. At the Berkeley ILP (Industrial Liaison Program, March 11th, 1998), Joe Hellerstein of UC Berkeley described an approach to visualizing and monitoring database queries as they progress (the Control project). He called it a ``crystal ball,'' as opposed to a ``black box.'' This is a wonderful metaphor and one which we believe applies as well to the systems design process. Unlike a black box, a crystal ball lets you view progressively more refined representations of the data in which you are interested (from a database query in his case, simulations and program analyses in ours), instead of just the final, complete answer. We are also disconcerted by the lack of attention to fluidity and usability of many of our tools. A secondary goal of ours is to experiment with new ideas for user input and navigation. We think these issues are ultimately inseparable from the visualization issues in which we are interested. One of the ideas we will be exploring in Diva is the use of sketch-based (free-hand) input to design and visualization tools. Our adoption of sketch and gesture input is inspired by the work of James Landay on sketching user interfaces (Landay and Myers 95). We have constructed a sketch and gesture-recognition sub-system that we can use to experiment with adding this kind of "informal" input to design and visualization tools. And most of all, we want to produce something that's useful. We aim to produce tools that allow a designer to try out different ideas and to construct their own visualizations. These tools need to be fairly complete, in that they do everything that you want, and maybe more -- for example, a graph visualizer without a browser is only half of the solution. They need to be cleanly componentized, so that they can be used without the "buy-in" problem, where a user must commit totally to our data formats and APIs to the exclusion of others. Finally, they need to be extensible, so that missing pieces can easily be added when needed. ArchitectureThe high-level Diva architecture is fundamentally based on the principle of separation of data and presentation. We have extended this well-established principle to support our vision of the ideal design and visualization architecture (see figure). In essence, it consists of a collection of loosely-coupled components, that communicate and collaborate to produce meaningful visual presentations. Any given visualization system or tools is constructed from a set of these components -- some general-purpose and some purpose-written -- "glued" together in useful ways. 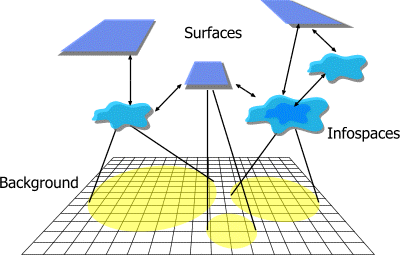 Infospaces consist, in a typical incarnation, of a model (in the sense of MVC, model-view-controller), and some added infrastructure. Associated with the model is a historical context, containing knowledge about the evolution of the space, such as the agents responsible for modifying it and dependencies between actions on the model's state. We will use this to experiment with ideas such as non-linear and context-sensitive design exploration (including "undo"), and collaborative group-awareness. Surfaces are, in similar fashion, extensions of the "view" part of MVC. At its simplest, a surface will be a wrapper around a visual component, such as Swing's JTree or Diva's JGraph. Infospaces are, in general, highly-dynamic and flexible. Any element of an infospace can hierarchically contain other infospaces, or contain references to them. We define a reference as a weak relation; any infospace can be contained by zero or one other infospaces, but can be referenced by many. We believe that the complexity of real design data mandates arbitrary and non-committed structuring of infospaces. For example, an infospace may in fact contain nothing but information that it derived from one or more other infospaces, allowing arbitrarily complex filtering and analysis systems to be built. One of the challenges in the implementation of the visualization architecture is the structuring, presentation and navigation of these relationships between infospaces. An infospace is also assumed to contain information that is both incomplete and evolving -- the "crystal ball," in other words. This understanding of incomplete and changing information is built into the core of Diva, to enable us to accomplish the goals we have outlined above. Surfaces continue the theme of incomplete and evolving data, by being able to display partial information and being able to update their display in useful ways as they receive new data from infospaces. In general, infospaces and surfaces can be distributed across a network, and we will be exploring the use of Javaspaces and Sun's distributed event model as one substrate for implementation of distributed visualization. A component architecture is, of course, useless without a common language for communication between components. We have identified the notion of a protocol, or high-level data type, as the basis for this language. A protocol consists, in effect, of the interfaces between a model and its view -- that is, two APIs, one for querying and modifying data, and one for notification of changes to data. The protocol that will be implemented by the Diva Graph package, for example, is that of hierarchical graphs. Other protocols that we expect to produce are multi-variate data, formatted text, and array-structured data. As it happens, any of these latter protocols can be expressed in terms of the hierarchical graph protocol by viewing graphs as entities and relations that map into visual constraints, and we will be exploring this issue with a view to discovering the limits of this very fundamental characterization of visualization. Driving projectsTo scope our work in visualizing the structure and behavior of complex systems, we are beginning by focusing on two application areas:
There are numerous other areas we would hope to explore in the area of complex systems design, including group awareness applications for collaboration, visualization of the evolution of the design repository, and algorithm animation. We are always interested to hear from people working in these areas or to discuss possible collaborative work. Design and development philosophyWe are taking what we believe to be a modern and open development approach to Diva. This approach has several aspects. First, we use component-centered design practices. Components reduce brittleness by encouraging composition instead of sub-classing. In contrast to frameworks, components make fewer assumptions about the way they will be used in future. Components adapt better to change, requiring only facades or adapters, whereas frameworks tend to require more substantial changes. To encourage clarity in the component APIs, we use Java interfaces extensively. Because interfaces are independent of implementation concerns, the understanding of the role of and collaboration between implementing components is much clearer. By aggressively pursuing these notions, we hope to avoid the "buy-in" problem that characterizes so many other frameworks. Second, we treat Diva as working software. We produced our first release, the "hard-hat" release, only three months after starting the project in earnest, and we aim to cycle through a "stable" minor release every six to eight weeks. We also produce a new "snapshot" release every few days, so that anyone that is interested in the current state of the system can download it any time. These releases are available at
We apply a similar principle of openness to the design and the APIs. We have adopted the design and code inspection process developed in the Ptolemy project, in which reviewed classes and packages are given a simple "rating" according to their progress from rough outline to polished software. We also welcome external input during this process. References
|