4.2 Dynamic scheduling
The relative firing rates of the different graphs may not be known exactly. The timing of graphs AB and CDE could be controlled by separate hardware clocks which, even though they may have very fine tolerances, will never be exactly synchronized. In this case it is not possible to exactly determine relative firing rates statically, thus requiring dynamic, run-time scheduling.
If the uncertainty in the relative rates is small, for example AB fires 160 or 161 times for every 147 firings of CDE, then the methods described by Kuroda and Nishitani [10] could be used. A set of 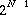 static schedules is constructed for a N-task system. In this case, the two schedules would be 160(3(A)2(B))147(CDE) and 161(3(A)2(B))147(CDE). Measurements from a hardware timer determine which of these schedules is executed next. The major drawback of this approach is that the complexity grows exponentially with the number of tasks.
static schedules is constructed for a N-task system. In this case, the two schedules would be 160(3(A)2(B))147(CDE) and 161(3(A)2(B))147(CDE). Measurements from a hardware timer determine which of these schedules is executed next. The major drawback of this approach is that the complexity grows exponentially with the number of tasks.
A more general dynamic scheduling scheme could use a real-time operating system that provides prioritized, preemptive scheduling. By using rate-monotonic priority assignment [9], in which tasks with higher rates are given higher priority, the operating system will provide the necessary run-time interleaving in such a way that all deadlines will be met if possible. If bounds on the firing rates and execution times of the tasks are available, then it is possible to guarantee that all deadlines will be met.
Preemptive rate-monotonic scheduling can be useful even with incomplete timing information. Because priorities are fixed, it is possible to predict which tasks will miss their deadlines in an overload situation. Firing rates need not be known exactly as long as there is an ordering of the rates. Execution times, which can be difficult to accurately estimate for programs written in C or other high level languages, are not used in the priority assignments.
Such a solution is attractive for its simplicity, but a large overhead is incurred for the operating system. Separate stacks must be maintained for the different tasks, and a large amount of context must be saved and restored when switching tasks. To avoid this overhead, a simple non-preemptive multitasking kernel can be used with rate-monotonic priorities[11]. By restricting the points at which a context switch is allowed to occur, a single system-wide stack will suffice and the context that must be saved and restored will be lighter, consisting of just a few machine registers.
Mapping Multiple Independent Synchronous Dataflow Graphs