




Page 18 out of 24 total pages
The synchronous dataflow (SDF) domain is useful for modeling simple dataflow systems without control, such as signal processing systems. Under the SDF domain, the execution order of actors is statically determined prior to execution. This results in execution with minimal overhead, as well as bounded memory usage and a guarantee that deadlock will never occur. Unfortunately, static schedules cannot be computed for all dataflow graphs. Dataflow graphs that cannot be statically scheduled should be executed using the process networks (PN) domain instead.
SDF is an untimed model of computation. All actors under SDF consume input tokens, perform their computation and produce outputs in one atomic operation. If an SDF model is embedded within a timed model, then the SDF model will behave as a zero-delay actor.
In addition, SDF is a statically scheduled domain. The firing of a composite actor corresponds to a single iteration of the contained model. An SDF iteration consists of one execution of the precalculated SDF schedule. The schedule is calculated so that the number of tokens on each relation is the same at the end of an iteration as at the beginning. Thus, an infinite number of iterations can be executed, without deadlock or infinite accumulation of tokens on each relation.
Execution in SDF is extremely efficient because of the scheduled execution. However, in order to execute so efficiently, some extra information must be given to the scheduler. Most importantly, the data rates on each port must be declared prior to execution. The data rate represents the number of tokens produced or consumed on a port during every firing. The data rates must be determined prior to execution and must be constant throughout execution. In addition, explicit delays must be added to feedback loops to prevent deadlock.
The first step in constructing the schedule is to solve the balance equations [47]. These equations determine the number of times each actor will fire during an iteration. For example, consider the system in figure 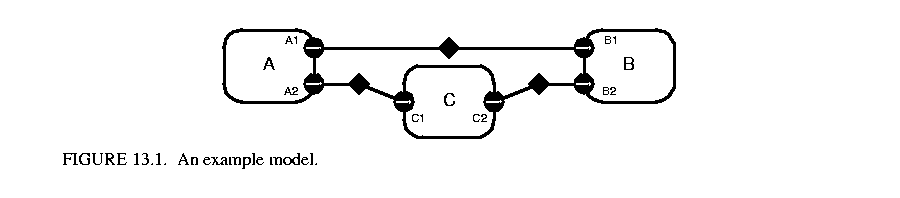 13.1. The scheduler will create the following system of equations, where ProductionRate and ConsumptionRate are declared properties of each port, and Firings is a property of each actor that will be solved for:
13.1. The scheduler will create the following system of equations, where ProductionRate and ConsumptionRate are declared properties of each port, and Firings is a property of each actor that will be solved for:
(39) Firings(A) ¥ ProductionRate(A1) = Firings(B) ¥ ConsumptionRate(B1)
(40) Firings(A) ¥ ProductionRate(A2) = Firings(C) ¥ ConsumptionRate(C1)
(41) Firings(C) ¥ ProductionRate(C2) = Firings(B) ¥ ConsumptionRate(B2)
These equations express constraints that the number of tokens created on a relation during an iteration is equal to the number of tokens consumed. These equations usually have an infinite number of linearly dependent solutions, and the least positive integer solution for Firings is chosen as the firing vector1.
In some cases, a non-zero solution to the balance equations does not exist. Such models are said to be inconsistent, and are illegal to execute under SDF. Inconsistent graphs inevitably result in either deadlock or unbounded memory usage for any schedule. As such, inconsistent graphs are usually bugs in the design of a model. However, inconsistent graphs can still be executed using the PN domain, if the behavior is truly necessary. Examples of consistent and inconsistent graphs are shown in figure 13.2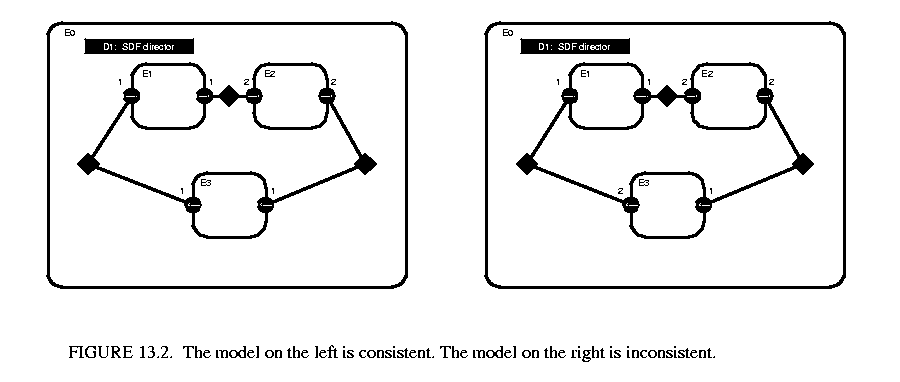 .
.
The second step in constructing an SDF schedule is dataflow analysis. Dataflow analysis orders the firing of actors, based on the relations between them. Since each relation represents the flow of data, the actor producing data must fire before the consuming actor. Converting these data dependencies to a sequential list of properly scheduled actors is equivalent to topologically sorting the SDF graph, if the graph is acyclic. Dataflow graphs with cycles cause somewhat of a problem, since such graphs cannot be topologically sorted. In order to determine which actor of the loop to fire first, a delay must be explicitly inserted somewhere in the cycle. This delay is represented by an initial token on some relation in the cycle. The presence of the delay allows the scheduler to break the dependency cycle and determine which actor in the cycle to fire first. Cyclic graphs not properly annotated with delays cannot be executed under SDF. An example of a cyclic graph properly annotated with a delay is shown in figure 13.3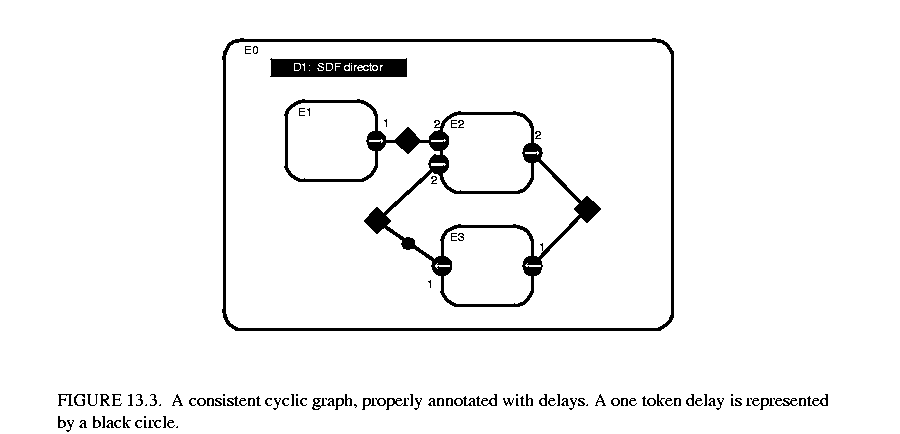 .
.
The SDF kernel package implements the SDF model of computation. The structure of the classes in this package is shown in figure 13.4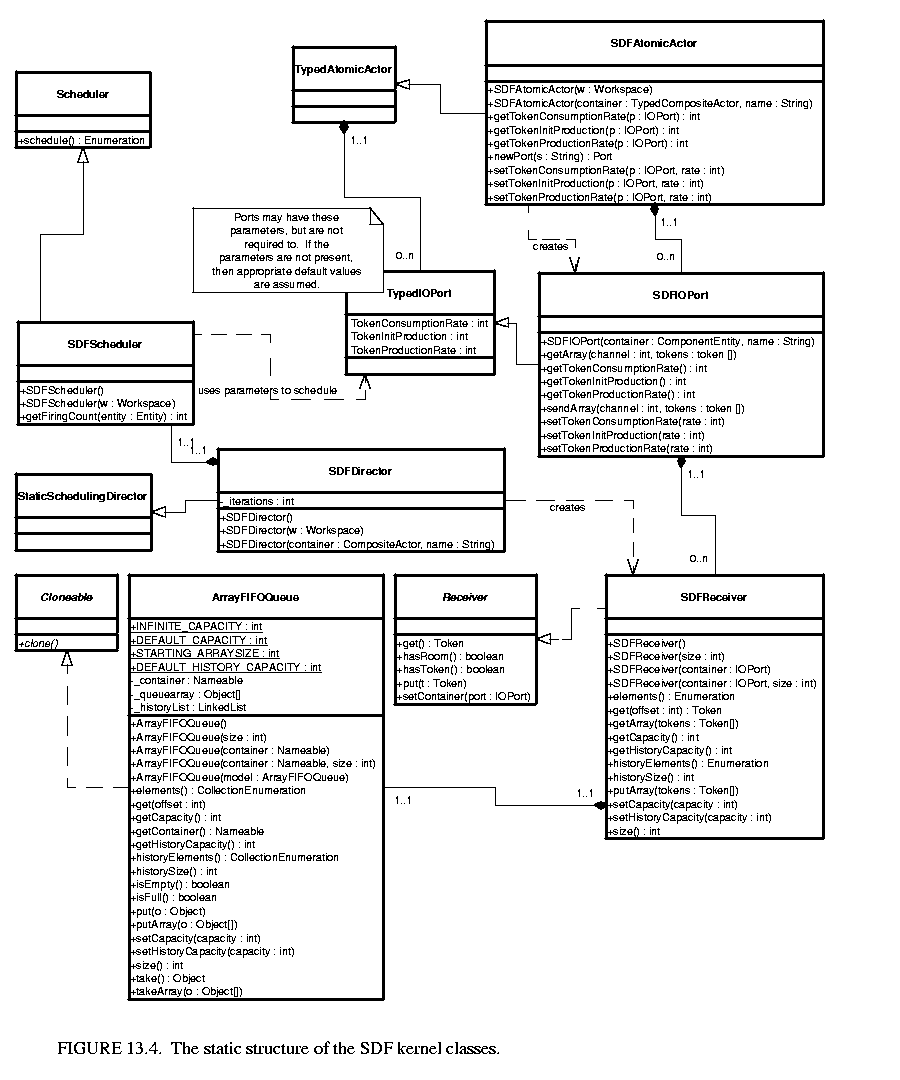 .
.
The SDFDirector class extends the StaticSchedulingDirector class. When an SDF director is created, it is automatically associated with an instance of the default scheduler class, SDFScheduler. This scheduler is intended to be relatively fast and valid, but not optimal in all situations. As such, future development will likely result in a wide range of schedulers with difference performance goals and trade-offs. The SDF scheduler does not currently restrict the schedulers that may be used with it.
The director has a single parameter, iterations, which determines a limit on the number of times the director wishes to be fired. After the director has been fired the given number of times, it will always return false in its postfire() method, indicating that it does not wish to be fired again. This parameter must contain a non-negative integer value. The default value is an IntToken with value 0, indicating that there is no preset limit for the number of times the director will fire. Users will likely specify a non-zero value for the number of iterations for the toplevel composite actor. When used this way, this parameter acts similarly to the Time-to-Stop parameter in Ptolemy Classic.
The newReceiver() method in SDF directors is overloaded to return instances of the SDFReceiver class. This receiver contains optimized method for reading and writing blocks of tokens. For more information about SDF receivers and the extra methods that they support, see section 13.2.3.
The basic SDFScheduler derives directly from the Scheduler class. This scheduler provides unlooped, sequential schedules suitable for use on a single processor. No attempt is made to optimize the schedule by minimizing data buffer sizes, minimizing the size of the schedule, or detecting parallelism to allow execution on multiple processors. We anticipate that as these schedulers become interesting, they will be added.
The scheduling algorithm is based on the simple multirate algorithms in [47]. Currently, only single processor schedules are supported. The multirate scheduling algorithm relies on the actors in the system declaring the data rates in each port. If the rates are not declared, then the scheduler assumes that the actor is homogeneous, meaning that it consumes exactly one token from each input port and produces exactly one token on each output port.
Data rates on ports are specified using three parameters: tokenConsumptionRate, tokenProductionRate, and tokenInitProduction. The production parameters are valid only for output ports, while the consumption parameter is valid only for input ports. If a parameter exists that is not valid for a given port, then the value of the parameter must be zero, or the scheduler will throw an exception. If a valid parameter is not specified when the scheduler runs, then appropriate values of the parameters will be assumed2, however the parameters are not then created.
In Ptolemy classic, hierarchical SDF models were generally flattened prior to scheduling. This technique allowed the most efficient schedule to be constructed for a model, and avoided certain composability problems. In Ptolemy II, this algorithm can be replicated by using transparent composite actors to define the hierarchy. However, Ptolemy II also supports a stronger version of hierarchy, in the form of opaque composite actors. In this case, the scheduler needs to do a little more work. Prior to scheduling a graph containing opaque composite actors, the scheduler queries each contained opaque composite actor that may contain another scheduler and calls schedule() on that scheduler. The SDF scheduler also creates and sets the appropriate rate parameters on any ports it encounters that are contained within its director's container.
SDF graphs should generally be strongly connected. If an SDF graph is not strongly connected, then there is some concurrency between the disconnected parts that is not captured by the SDF rate parameters. In such cases, another model of computation (such as process networks) should be used to explicitly specify the concurrency. As such, the current SDF scheduler disallows disconnected graphs, and will throw an exception if you attempt to schedule such a graph. However, sometimes it is useful to avoid introducing another model of computation, so it is likely that a future scheduler will allow disconnected graphs with a default notion of concurrency.
Notice that it is impossible to set a rate parameter on individual channels of a port. This is intentional, and all the channels of an actor are assumed to have the same rate. For example, when the AddSubtract actor fires under SDF, it will consume exactly one token from each channel of its input plus port, consume one token from each channel of its minus port, and produce one token on each channel of its output port. Notice that although the domain-polymorphic adder is written to be more general than this (it will consume up to one token on each channel of the input port), the SDF scheduler will ensure that there is always at least one token on each input port before the actor fires.
Ports should, in general, be connected under the SDF domain. A regular port that is not connected cannot be fulfilled by the SDF scheduler and the scheduler will always throw an exception. The SDF scheduler also detects multiports that are not connected to anything (and thus have zero width). Such ports are interpreted to not actually exist, and are legal under SDF. The scheduler will ignore the presence of a disconnected multiport.
Unlike most domains, multirate SDF systems tend to produce and consume large blocks of tokens during each firing. Since there can be significant overhead in data transport for these large blocks, SDF ports and receivers have optimized methods for sending and receiving a block of tokens en masse.
The SDFReceiver class implements the Receiver interface. Instead of using the FIFOQueue class to store data, which is based on a linked list structure, SDF receivers use the ArrayFIFOQueue class, which is based on a circular buffer. This choice is much more appropriate for SDF, since the size of the buffer is bounded, and can be determined statically3. Circular buffers also have less memory and object allocation overhead for a queue of a given size.
In addition to the normal receiver methods, the SDFReceiver provides sendArray() and getArray() methods. These two methods operate on arrays of tokens identically to the ways the send and get methods operate on individual tokens. Calling the sendArray() method on an array of tokens is equivalent to calling the send() method on each element of the array, only faster4.
The SDFIOPort class extends the TypedIOPort class. It adds two methods, sendArray() and getArray(). If the remote port contains an SDF receiver, then the receiver's sendArray() method will be used instead of the send() method. The getArray() method operates similarly. Currently, SDF ports do not support block operations on the history tokens of the ports.
The ArrayFIFOQueue class implements a first in, first out (FIFO) queue by means of a circular array buffer. Functionally it is very similar to the FIFOQueue class. It provides a token history and an adjustable, possibly infinite, bound on the number token it contains.
If the bound on the size is finite, then the array is exactly the size of the bound. In other words, the queue is full when the array becomes full. However, if the bound is infinite, then such an array cannot be created! In this case, the circular buffer is given a small starting size, but allowed to grow. Whenever the circular buffer fills up, it is copied into a new buffer that is twice the original size.
The SDFAtomicActor class extends the TypedAtomicActor class. It exists mainly for convenience when creating actors in the SDF domain. It overrides the newPort() method to create SDF ports. It also provides methods for setting and accessing the rate parameters on the actor's ports.
The firing vector is also known as the repetitions vector.
2The assumed values correspond to a homogeneous, zero-delay actor. Input ports are assumed to have a consumption rate of one, output ports are assumed to have a production rate of one, and no tokens are produced during initialization.
3Although the buffer sizes can be statically determined, the current mechanism for creating receivers does not easily support it. The SDF domain currently relies on the buffer expanding algorithm that the ArrayFIFOQueue uses to implement circular buffers of unbounded size. Although there is some overhead during the first iteration, the overhead is minimal during subsequent iterations (since the buffer is guaranteed never to grow larger).
4The array operations in ArrayFIFOQueue use the java.lang.system.arraycopy method. This method is capable of removing certain checks required by the Java language. On most Java implementations, this is significantly faster than a hand coded loop for large arrays. However, depending on the Java implementation it could actually be slower for small arrays. The cost is usually negligible, but can be avoided when the size of the array is small and known when the actor is written.
ptII at eecs berkeley edu Copyright © 1998-1999, The Regents of the University of California. All rights reserved.